A lot of teams realize they need social media crisis management at the worst possible moment.
It usually starts small. A frustrated customer posts a detailed complaint on Reddit about a product change, an integration failure, or a billing surprise. Someone else adds screenshots. A few power users pile on. Then a creator on X picks it up, strips out the nuance, and turns it into a simple story your brand definitely doesn’t want told about it.
By the time someone on your team says, “Should we respond?”, you’re already late.
I’ve seen the same pattern across B2B SaaS, ecommerce, and agency environments. The brands that hold up under pressure aren’t always the ones with the best PR people. They’re the ones with a clear operating system. They detect trouble early, know exactly who owns the next move, and reply in a way that sounds human instead of defensive.
Your Playbook Starts Before The Crisis Hits
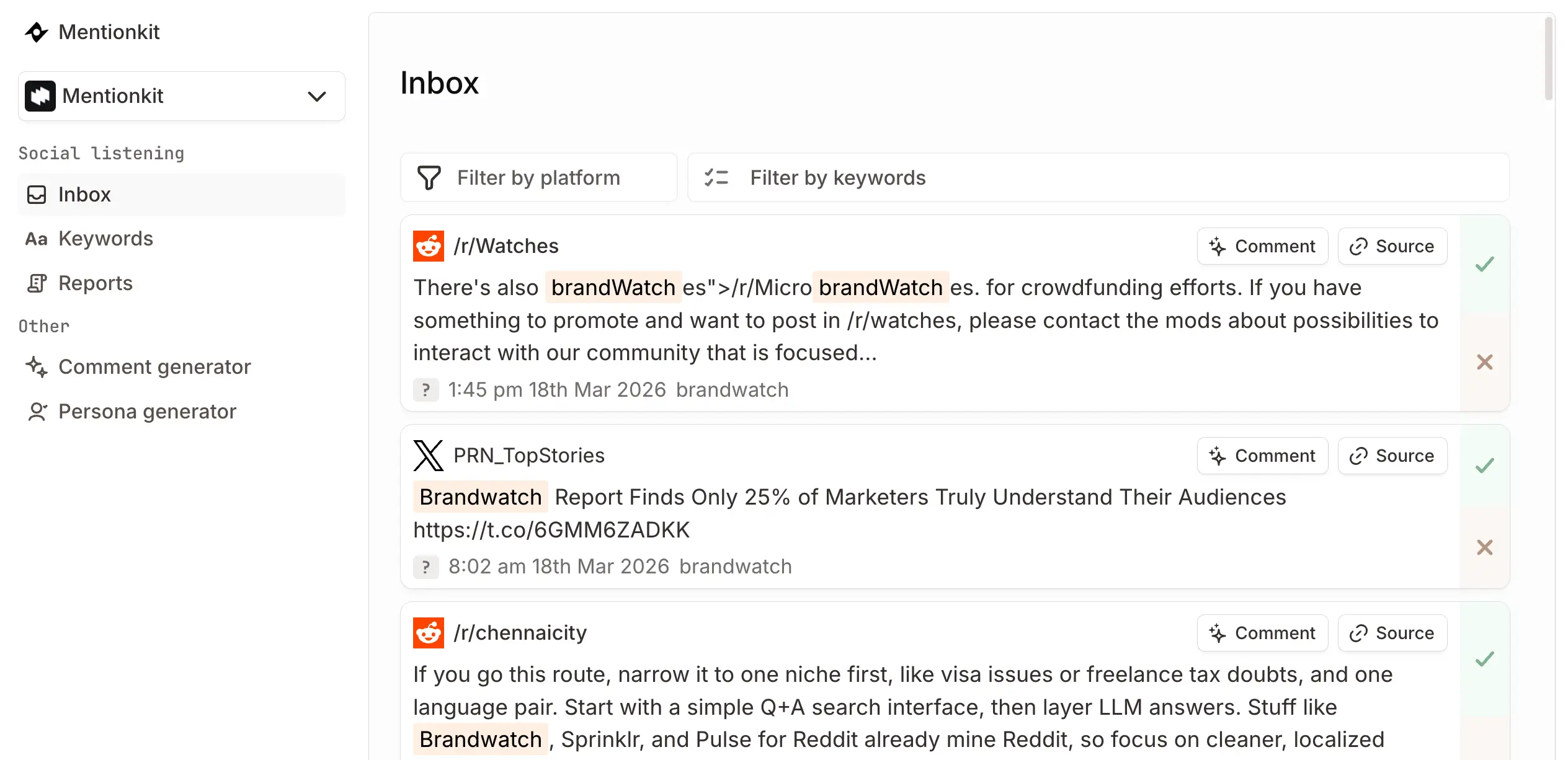
Monday morning. A niche subreddit starts criticizing your latest product update. At first it’s one thread. By lunch, a screenshot escapes the subreddit, lands on X, and people who have never used your product start commenting as if they’ve been wronged personally. Support is swamped. Sales asks what to tell prospects. Your CEO wants a draft statement in ten minutes.
That isn’t the time to build a process.
Why preparedness became a real business function
This isn’t paranoia. It’s operational hygiene. The social media crisis management market is projected to reach USD 10.2 billion by 2032, growing at a CAGR of over 21%, which tells you companies now treat reputation protection as infrastructure, not a nice-to-have.
In practice, that means your crisis plan needs to exist before the first angry post gets traction. Not in someone’s head. Not in a stale Notion page no one has opened since last year. It needs owners, thresholds, draft language, approval rules, and a place where the team can work without improvising every decision.
A useful mindset comes from broader risk planning, not just social. The same logic behind early planning to prevent commercial crises applies here too. Pressure exposes weak coordination. It doesn’t create it.
Practical rule: If your team still has to decide who approves a public response after the issue is already trending, your plan is incomplete.
What a real playbook includes
Organizations often overfocus on the public statement and underbuild the machinery behind it. The statement matters, but it only works when the internal sequence is already clear.
Your baseline playbook should include:
- Detection rules: Which keywords, executives, products, communities, and competitor-adjacent topics are monitored.
- Escalation thresholds: What counts as noise, what becomes an incident, and what triggers executive visibility.
- Role clarity: Who drafts, who approves, who posts, who coordinates with support, legal, and product.
- Platform guidance: Reddit doesn’t reward the same tone LinkedIn does. X doesn’t allow for long explanations without structure.
- Recovery steps: What happens after the first response, including updates, follow-up, and post-mortem review.
What works and what fails
What works is boring. A rehearsed process. Clear ownership. A calm first response that acknowledges the issue without overpromising. Consistent updates. Internal alignment.
What fails is also predictable:
- Silence while waiting for perfect information
- Three different teams replying with three different messages
- Deleting criticism that should have been answered
- Using legal language when customers want plain English
- Treating every complaint like a five-alarm fire
Social media crisis management is less about dramatic rescue moves and more about disciplined execution. When the pressure spikes, your team falls back to whatever process already exists. If nothing exists, panic becomes the workflow.
Setting Up Your Crisis Detection System
You can’t contain what you don’t see.
Most brands monitor direct mentions and stop there. That’s not enough. The post that turns into your problem often doesn’t tag you, doesn’t spell your brand correctly, or starts in a community your marketing team never checks.
Watch three signal types
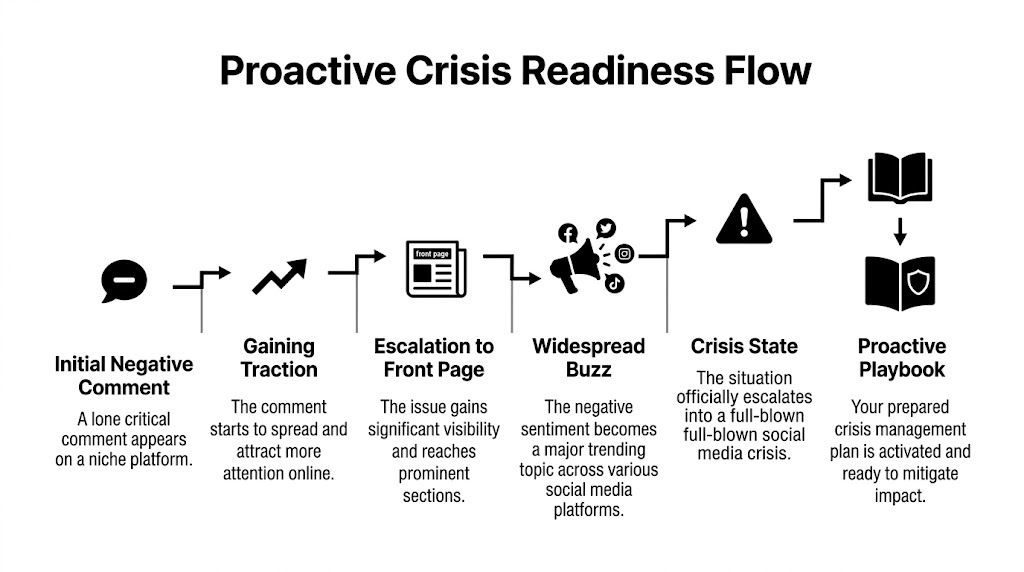
A solid detection setup tracks more than brand mentions. I break it into three buckets.
-
Direct signals
These are the obvious ones. Brand name, product names, executive names, campaign names, common misspellings, and terms like “broken,” “scam,” “outage,” or “refund” next to your company. -
Indirect signals
These are nearby issues that can spill onto you. A partner integration fails. A reseller misstates your policy. A competitor crisis pulls your brand into comparison threads. A review site discussion starts framing your category in a way that puts you on defense. -
Adjacent signals
These are broader conversations that create the context for a crisis. Regulatory chatter. Industry complaints. Privacy concerns. Shipping delays across a platform ecosystem. If the market starts worrying about a category issue, your brand can get dragged in even when you didn’t trigger it.
Many teams miss the story early. They wait for their name to trend instead of noticing the environment changing around them.
Set thresholds before emotions get involved
Detection gets messy when every angry post feels urgent. You need thresholds that decide what matters before the team is stressed.
One expert framework flags escalation when you see a 3x spike in mentions or a 20% sentiment drop within an hour, and it also notes that 70% of teams lack clear tiers, which leads to delays and can amplify virality significantly, according to Sprinklr’s crisis management framework.
That matters because a threshold prevents two common mistakes. First, overreacting to isolated criticism. Second, dismissing a real signal as “just social being social.”
The best alert is not the loudest one. It’s the one your team trusts enough to act on immediately.
Build the monitoring workflow
For B2B and ecommerce teams, I like a simple setup:
- Platform layer: Monitor Reddit, X, LinkedIn, review communities, and any niche forums where your buyers or users gather.
- Keyword layer: Track exact brand terms, product names, exec names, support phrases, and comparison keywords.
- Intent layer: Separate complaint language from normal discussion. “Anyone else seeing this bug?” is more urgent than a casual mention.
- Routing layer: Send higher-risk alerts to a shared channel where social, support, and comms can see the same context.
If you’re tightening up this foundation, it’s worth reviewing a more detailed guide to brand mention monitoring so your team doesn’t build blind spots into the system from day one.
Optimize for speed, not volume
A Pew Research Center finding cited by Konnect Insights says 68% of American adults get news from social media, and that same source notes that detecting an issue even 30 minutes earlier can be the difference between a manageable situation and a viral catastrophe in crisis conditions, as discussed in Konnect Insights on social media analytics in crisis management.
That doesn’t mean you need more dashboards. It means you need fewer false alarms and faster context.
A common practical test is simple. When an alert fires, can the on-call person answer these questions in under five minutes?
- Where did this start
- Is it spreading across more than one platform
- Are real customers involved, or mostly spectators
- Is the complaint factual, emotional, or both
- Do we need public acknowledgment now
If the system can’t answer those quickly, it isn’t a detection system. It’s just noise collection.
Building Your Escalation Matrix And Team
Alerts don’t solve chaos. They just start the clock.
The first breakdown in a social media crisis rarely happens in public. It happens inside the company, when social asks support for facts, support asks product for answers, legal wants to review everything, and nobody knows who can publish a response.
Why vague ownership burns time
I’ve seen smart teams lose precious time because everyone was “involved” and nobody was clearly accountable. A crisis plan fails when it names departments instead of people.
You need three roles at minimum:
- First Responder: Usually social, community, or whoever sees the issue first. This person gathers facts, captures screenshots, and opens the incident.
- Comms Lead: Owns message quality and consistency across channels.
- Crisis Owner: Makes the final call when trade-offs get sharp. On smaller teams, this might be a marketing lead or founder. On larger teams, it may be a VP or executive sponsor.
A separate reviewer from legal or product can join based on the incident type. But if too many people become approvers, response speed collapses.
Use simple tiers, not clever ones
Three levels are enough for most SaaS and ecommerce teams. Low, Medium, High. Anything more detailed usually gets ignored when things get tense.
Here is a practical model a smaller team can adopt.
| Crisis Level | Example | First Responder | Action & Approval |
|---|---|---|---|
| Low | Isolated misinformation or a single complaint thread with limited spread | Social or community manager | Verify facts, draft correction or acknowledgment, get comms lead review, respond on the original platform |
| Medium | Growing complaints across more than one channel, recurring bug reports, or partner-related backlash | Social lead or comms lead | Pause scheduled content, align with product or support, publish acknowledgment, use cross-functional review before posting |
| High | Viral boycott language, executive controversy, legal or ethical concerns, or mainstream attention | Comms lead with executive sponsor | Open full incident channel, involve legal and leadership, publish approved statement, centralize all outbound communication |
Match triggers to action
An escalation matrix only works if it tells people when to move up a tier. Otherwise the team debates severity while the internet keeps posting.
A useful template can save time if you’re formalizing this internally. DocsBot has a practical guide to create an effective escalation process template that maps well to crisis workflows.
If your team collaborates inside shared tools, make sure access isn’t bottlenecked. A clean approval chain falls apart when the right people can’t see the same incident thread, which is why shared workspace permissions matter. This is one of those operational details teams often overlook until a real incident hits. If you’re reviewing collaboration setup, check how to share access with your team.
A good escalation matrix removes judgment from the first ten minutes. People still use judgment later. But the first moves should be automatic.
What the matrix should prevent
The matrix isn’t there to make you sound organized. It’s there to prevent two costly habits.
First, overreaction. Not every critical post needs an executive statement. If you escalate everything, the team gets numb and slows down.
Second, underreaction. A genuine issue can look small at the start because only one platform is talking about it. The matrix forces a review before someone dismisses it too early.
The strongest social media crisis management systems don’t create bureaucracy. They create clarity. Under pressure, clarity is speed.
Real-Time Response Templates And Tactics
Once the crisis is real, your response has to do three things fast. Acknowledge the issue, show that a real team is working on it, and avoid making the situation worse.
That last part matters more than people admit. Most public replies don’t fail because they’re too short. They fail because they’re evasive, defensive, or weirdly polished in a moment that calls for plain language.

Start with the right response type
Most crisis replies fit into one of three patterns.
Acknowledgment
Use this when the facts are still coming together.
We’re aware of reports about [issue]. Our team is reviewing what happened now. We’ll share an update here as soon as we have confirmed details.
Apology with ownership
Use this when your team clearly caused the issue.
We got this wrong. We’re sorry for the impact on customers. We’ve paused [relevant action], we’re fixing the underlying issue, and we’ll post the next update by [timeframe].
Clarification
Use this when false information is spreading and you need to correct it without sounding combative.
We want to clarify one point. [Concise factual correction]. We understand why people are asking questions, and we’ll keep updating this thread as we verify more information.
None of these are meant to sound corporate. They should sound like a responsible person speaking in public.
Channel tactics for a product bug crisis
Take a common SaaS problem. A release introduces a bug that blocks logins for some users. Support is already flooded. Reddit says your product is “down.” X says you’re hiding it. LinkedIn has prospects asking if the platform is reliable.
This is not one message copied across three platforms.
On X
X rewards speed and clarity. Say less, but say something useful.
A good first post might look like this:
- Acknowledge the issue: Confirm you’re aware.
- State current action: Tell users what the team is doing.
- Set update expectation: Give a clear place or thread for follow-up.
Example:
We’re aware some users are having trouble logging in after the latest update. The team is investigating now. We’ll post updates in this thread.
What not to do on X:
- Don’t argue with replies
- Don’t paste a legal disclaimer
- Don’t imply it’s limited if you haven’t confirmed that yet
On LinkedIn
LinkedIn usually needs more context, especially for B2B buyers, customers, and partners who care about stability and accountability.
A stronger LinkedIn post can include:
- What happened in plain terms
- Who is affected if known
- What the team has already done
- When the next update will appear
The tone can be more formal, but it still shouldn’t sound like it was written to avoid responsibility.
Keep the response workspace organized
Response quality depends on coordination. During a live incident, scattered drafts across Slack, email, and docs create version confusion fast.
I’ve found that teams do best when they run crisis communication from one shared workspace that shows the original mention, context around it, ownership, and reply history. That setup becomes your war room. One person drafts, one reviews, one approves, and everyone can see what has already been handled.
If you’re evaluating platforms that support that kind of workflow, this overview of top social listening tools for 2026 is a good starting point.
The speed requirement is real. Hootsuite reports that responding in under one hour can cut negative virality by 50%, and teams with a formal plan retain 75% of customer trust compared with 40% for teams that improvise, according to Hootsuite’s social media crisis management guidance.
Reddit needs respect, not spin
Reddit is where brand messaging goes to die if it sounds staged.
If the crisis started in a subreddit, don’t show up with broad marketing language. Answer the actual complaint. Be specific about the issue. If a fix is underway, say so. If you don’t know yet, admit that and come back with an update when you do.
The fastest way to lose a Reddit thread is to sound like you’re replying for legal cover instead of to help the people in the thread.
A practical Reddit pattern looks like this:
- Open directly: “You’re right to flag this.”
- Address the substance: “The latest update caused login failures for some users.”
- State current action: “Engineering is working on it now.”
- Close with commitment: “I’ll update this thread when we have the next confirmed fix.”
Later in the response cycle, it helps to review how other teams handle live situations and video-led explanations. This example is useful for studying tone and pacing in public response:
What not to say
There are a few lines I would strike from almost any crisis draft:
- “We take this very seriously” if nothing concrete follows
- “This appears to be isolated” before you’ve confirmed scope
- “Please contact support” as your only public answer
- “We apologize if anyone was offended” because that’s not an apology
Good social media crisis management sounds measured, accountable, and current. It doesn’t sound perfect. Perfect is suspicious during a live incident.
Steps For Remediation And Recovery
The first public response stops the bleeding. Recovery is what proves the brand deserves trust again.
A lot of teams treat recovery like a cooldown period. It isn’t. It’s the part where your original promises either become credible or collapse. If you said you’d investigate, publish what you found. If you said you’d fix something, show the fix. If users carried the burden of discovering the issue for you, follow up with them directly.
A three-step recovery checklist
Publish the resolution clearly
When the fix is ready, say exactly what changed. Don’t force customers to infer closure from silence.
For SaaS, that might mean a post explaining the bug is resolved, any remaining limitations, and what customers should do next. For ecommerce, it may mean a policy correction, shipping update, or product guidance. Either way, the wording should close the loop with the same audiences that saw the original problem.
Follow up with the people closest to the issue
The loudest critics aren’t always trolls. Often they’re your most attentive customers.
Go back to the original Reddit thread. Reply to the X posts that gained traction. Message the customer who posted the detailed breakdown if direct outreach makes sense. Not with a canned “just checking in” note. With a real update tied to the issue they raised.
That move does two things. It shows accountability, and it signals to bystanders that the brand didn’t disappear once the pressure faded.
Recovery gets stronger when the people who raised the issue can see that their effort led to a real change.
Monitor the reaction after the fix
A resolved issue doesn’t mean sentiment resets instantly. Watch whether people are acknowledging the change, whether confusion still exists, and whether second-order complaints are forming around how you handled the situation.
Use that monitoring to answer practical questions:
- Are customers sharing that the fix worked
- Are old complaints still circulating without updated context
- Does the team need one more public clarification
- Are support and sales using the same recovery language
What recovery looks like when it’s working
You don’t need a victory lap. In fact, that’s usually a mistake.
What you want is a visible pattern of follow-through. People saw the issue, saw the response, and then saw you finish the job. That’s where trust starts to rebuild. In some cases, a well-handled recovery turns frustrated users into credible advocates because they watched the company behave responsibly under stress.
That doesn’t happen because the statement was polished. It happens because the response and the remediation matched.
Conducting A Blameless Post-Mortem Analysis
Once the incident is over, the instinct is to move on. Resist that. A crisis you don’t examine becomes training data for the next failure.
The best post-mortems are blameless and unsentimental. They focus on decisions, timing, systems, and handoffs. Not on who to embarrass.
Ask five hard questions
When did we actually know
Look at the earliest detectable signal. Was it a Reddit post, a support ticket trend, a spike in negative replies, or an internal report that didn’t reach social fast enough?
This is your real detection point, not the moment leadership noticed.
How long did response approval take
Map the gap between detection and first public acknowledgment. Then map the gap between draft creation and approval.
If approval took too long, don’t just say “we need to be faster.” Identify the exact blockage. Missing owner, unclear legal trigger, too many reviewers, or poor internal visibility.
Did our first message match the situation
Review the first public reply against the actual issue. Was it too vague. Too defensive. Too narrow. Too polished.
One useful finding from Penn State Extension is that transparent communication on social media significantly lessened consumers’ perceived crisis responsibility for a brand, which is a strong reminder that accountability can reduce blame when teams communicate clearly, as discussed in Penn State Extension’s guidance on using social media in crisis management and communications.
Track the metrics that change behavior
You don’t need a giant reporting deck. You need a handful of measures that help the next response improve.
Keep a record of:
- Time to Detection: When the first meaningful signal appeared versus when the team recognized it
- Time to Response: When the first public acknowledgment went live
- Peak negative mention period: When pressure was highest and on which channels
- Sentiment recovery window: When conversation began moving back toward normal
- Operational breakdowns: Missing access, duplicate replies, approval delays, unclear ownership
What should change before the next incident
Every post-mortem should end with concrete revisions. Update thresholds. Rewrite weak templates. Narrow the approver list. Add missing keywords. Train the person who froze. Fix the handoff between support and social if that’s where things broke.
A blameless post-mortem isn’t soft. It’s rigorous. It just treats process failure as something to repair instead of something to shame.
If you do social media crisis management long enough, you stop asking whether another incident will happen. It will. The useful question is whether the next one will catch your team improvising or prepared.
The teams that handle crises best usually aren’t the loudest online. They’re the ones with clean monitoring, clear ownership, and a workspace built for fast decisions. If you want a practical way to track brand and high-intent conversations across Reddit, X, LinkedIn, and Hacker News, Mentionkit gives teams one place to monitor, prioritize, collaborate, and respond before a small issue turns into a bigger one.